Windows 2003 Cluster : MPIO Issues
I came across an odd issue not that long ago, with an Exchange 2007 SP1 CCR cluster running on Windows Server 2003 R2 SP2 x64.Hardware specifications for this issue were as follows:
- The hardware was HP C-Class BL680c Blades in a C7000 chassis.
- Network connectivity for the chassis was handled by dual HP Virtual Connect (VC) modules
- Fibre connectivity supplied by HP VC 4G/B Fibre Modules using NPIV.
- Approx 25 EVA 3000 disks were presented to each node, the HP EVA DSM was installed on the cluster nodes.
Symptoms
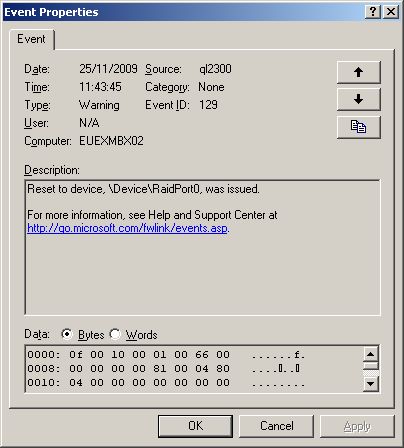
The following events would be reported in the event log:
- Event ID 129 : ql2300 Warning “Reset to device, \Device\RaidPort0, was issued
- Event ID 11 : ql2300 Error “The driver detected a controller error on \Device\RaidPort0.”


With no patter, or discernable cause the cluster would either:
- Fail-over to the passive node.
- The cluster service on the passive node woud stop, along with all Exchnage resources
This would happen several times a week.
The following events would be logged in the event log:
- Event ID 1118 : clusNet Error “Cluster service was terminated as requested by Node 1.”
- Event ID 1026 : hpevadsm Error “The Driver has detected a path failur/removal to LUN ID


Fainlly, MPIO errors were logged in the event log and disk paths would be missing:
- Event ID 17 : mpio Warning \Device\MPIODisk1 is currently in a degraded state. Once or more paths have failed, thoughthe process is now complete.
- Event ID 16 :mpio Warning “A fail-over on\Device\MPIODisk24 occurred”


These errors would be rported for multiple EVA disks at a time.
Cause
This is caused by thethe HP VC module firmware versions (both the Ethernet and F/C modules require updating – however this entails several more updates!)
Solution
- Update all of the individual server firmware in the chassi using the HP Firmware Maint. CD
- Update the HP Onboard Administrator
- Update th HP Virtual Connect Modules
Since following this ‘action plan’ from HP the issue wasresolved – no re-occurance in 7 weeks.